Evan Marie Carr
Project Portfolio
Filter by category:
NJATMDB
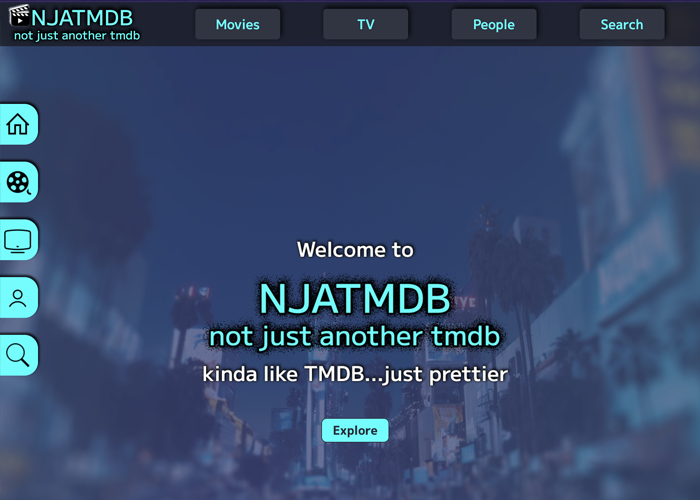
Discover "Not Just Another TMDB," a dynamic movie database application that brings movies, TV shows, and celebrities to your fingertips. With its sleek interface, you can effortlessly explore genres, categories, and trending content. Built using SvelteKit and Vite and empowered by the TMDB API, it offers a seamless, fully responsive experience across all devices. The modern, colorful design balanced by dark tones adds to the visual appeal. Experience entertainment like never before by visiting the live version of this intuitive and vibrant platform.
(read more)
Stefanuk

Snap-scroll site for musician, Misha V Stefanuk - A renowned jazz and classical pianist, organist, and composer, Misha Stefanuk has been a dynamic presence in the music industry since 1986. His contributions span over a hundred TV credits, including Good Morning America and One Life to Live. His versatility and ability to perform a wide range of music styles have made him a sought-after pianist and organist in Atlanta.
(read more)
Chakra UI
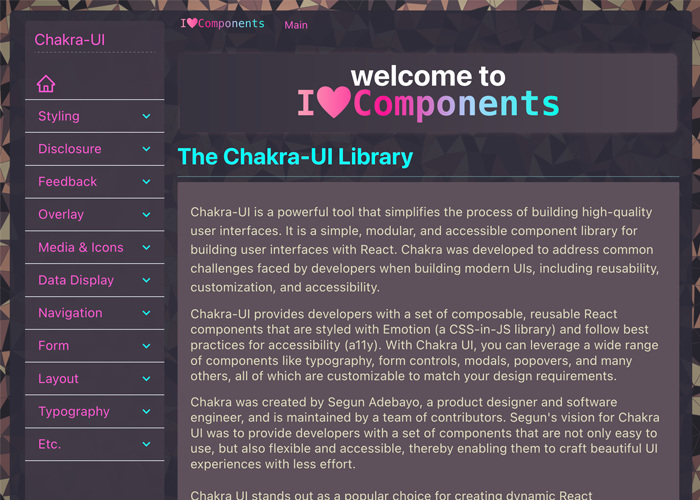
Immerse yourself in Evan Marie's intricate exploration of Chakra UI through the lens of a meticulously designed, fully responsive web portal. This robust platform teems with engaging examples and detailed interpretations of each unique component presented by Chakra UI. Contrary to the apprehension some developers might feel about using predefined component libraries, Evan elegantly underscores how such tools actually amplify creative potential. By streamlining the intricacies of user interface design, these libraries liberate developers to channel their energy towards enriching the functionality of their applications.
(read more)
Dreams
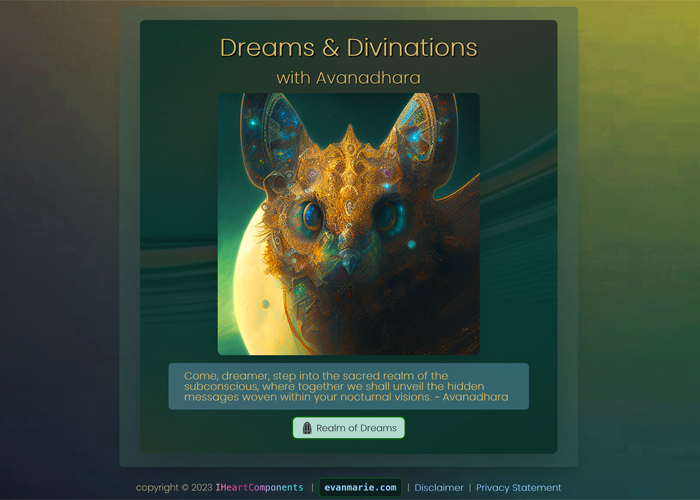
The current form is just the beginning for this dream interpretation web app. Evan Marie's vision for this project is to build a comprehensive dream interpretation application that utilizes machine learning as well as a wealth of Jungian analysis to provide users with a personalized explanation of their dreams. The current version of the application is a prototype that showcases Evan's adept use of React, TypeScript, and Chakra UI. The application is fully responsive and features a sleek, minimalist design. The user-friendly interface facilitates the input of dream details and the exploration of dream interpretations. Check back soon, as this project will grow to become a full social network for dream interpretation and journaling.
(read more)
Game Hub
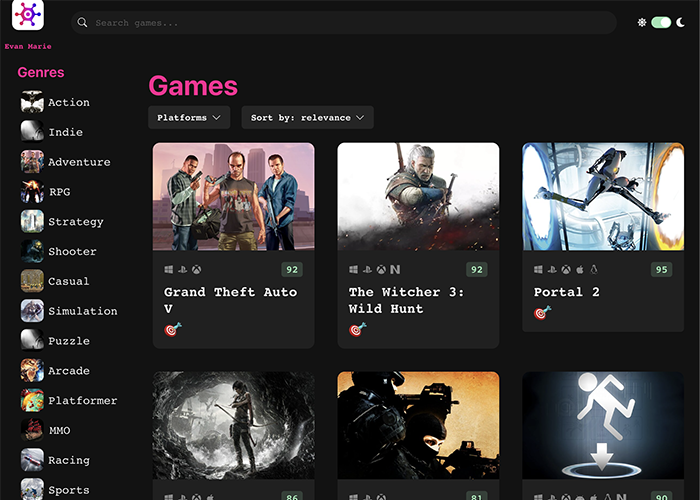
This is one of Evan's recent projects, which showcases her adept use of React, TypeScript, and Vite to build an engaging and design-forward game hub application. This user-friendly application facilitates the sorting, searching, and exploration of a vast array of games available from the Rawg API. Check out the application's intuitive interface and seamless functionality by visiting the live version hosted on Vercel.
(read more)
Web Scraping
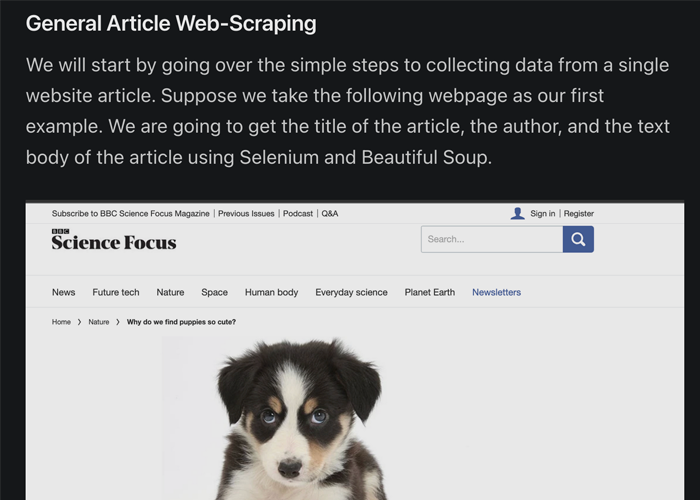
In this comprehensive article, Evan Marie dives deep into the world of web scraping using two powerful libraries: Selenium and Beautiful Soup. She provides a simplistic overview of the process which is substantial enough for anyone to get started. She argues that the ability to gather your own data is a crucial skill in data science. The article then delves into the technical aspects of web scraping, detailing how to collect data from a single website article and then expanding to performing a Google search and scraping results from that search. The article provides code snippets and visual aids for better understanding and suggests how this process can be automated and scaled for large amounts of data.
(read more)
Meta Prophet

Evan Marie investigates the effectiveness of the Prophet machine learning model (formerly known as fbprophet) for time series prediction, using three distinct datasets: Apple's stock prices, ecommerce sales, and energy consumption data. It offers an in-depth look at how Apple's stock price data is retrieved, visualized, and processed, then how Prophet is used to build a predictive model. Despite some criticisms of the Prophet model, Evan acknowledges the model's simplicity and speed.
(read more)
XGBoost

In this project Evan Marie delves into the world of time series prediction, focusing on the XGBoost model. Traditionally, LSTM and transformer models are the primary choices for time series prediction. However, Evan emphasizes the effectiveness of XGBoost, an 'extreme gradient boosting' library, in certain circumstances. The model's potency in handling regression and classification tasks is notable. She details her experience using an XGBoost Regression model to accurately predict energy usage in the UK, providing statistical proof for its effectiveness. The approach integrates feature engineering and machine learning tools, such as Scikit-Learn, to enhance prediction accuracy.
(read more)
PyTorch Prediction

Evan Marie Carr, provides a walkthrough of creating a basic Long Short-Term Memory (LSTM) neural network model to predict Ethereum prices using the PyTorch and PyTorch Lightning libraries, demonstrating how to gather, prepare, and engineer data, including gathering minute-by-minute data of Ethereum prices and creating a function to compile this data despite certain limitations from Yahoo Finance. Various aspects of the process, like data splitting and scaling, sequence creation, dataset creation, and LSTM model creation are discussed in detail. Additionally, Evan Marie incorporates PyTorch Lightning's extra steps for training, validation, and testing. The model is then trained with the results visualized subsequently. However, the article ends before explaining the process of interpreting the results and possible next steps.
(read more)
Yahoo! Finance

In this comprehensive guide, Evan Marie details the utilization of Python and Pandas to access financial data from Yahoo Finance, a valuable resource for the financial and crypto markets, currency exchange, mutual funds, and treasury yields. The author explores how to use the Python module yfinance to retrieve historical data. She describes methods to select specific date ranges for data, import high-frequency data, and understand stock splits and dividends. The guide also explains how to export stock data to various formats, including CSV, excel, SQL, JSON, and HTML, using Pandas. The article demonstrates how to import multiple stock tickers, import indexes like the S&P 500 and Dow Jones Industrial Average, and normalize this data to make meaningful comparisons.
(read more)
The Olympics

This project presents an extensive study focused on data import, data cleaning, data merging, statistical analysis, and advanced data visualization using Python, Pandas, and Seaborn. The project analyzes an exciting dataset containing information on all Olympic medal-winning athletes from the inception of the Olympics until the recent games. The goal is to uncover intriguing correlations and delve deep into the power of Python and Pandas for analytical tasks. The article offers an interactive Jupyter notebook link and a link for helpers.py, which contains useful functions that enhance readability and presentation of the dataframes. The author invites readers to explore the code, particularly the helper functions in helpers.py, while appreciating the data analysis and visualizations.
(read more)
Names

This article shares an in-depth exploration into a dataset from the US Government's www.data.gov website, specifically, the Baby Names data. Spanning from 1880 to 2021, the data consists of 142 files, each corresponding to a specific year, and containing baby names registered that year, along with the baby's gender and count of that particular name and gender combination. Although seemingly simple, the data provides countless social inferences and possibilities for feature engineering from just 3 columns. After combining these individual files into one consolidated dataframe and optimizing the memory footprint, the author initiates a fascinating exploration of trends and inferences from the data. Initial investigation reveals a total of 2,052,781 name and year combinations, representation of 142 different years, and 101,338 unique names in the dataset.
(read more)
JSON, Pandas, SQL

A comprehensive guide on working with big data using Python, Pandas, and SQLite3 to manage a SQL relational database. Evan emphasizes the efficiency and manageability of handling big data by storing them in SQL databases, retrieving specific data as needed. She illustrates these steps in which JSON data is converted into a Pandas dataframe, then smaller dataframes, and finally into tables within an SQL relational database. The project's data is sourced from the United Nations Economic Commission for Europe (UNECE) API, containing records for 52 countries over the span of 2000 to 2016.
(read more)
Data Cleaning

Evan Marie discusses the role of APIs and JSON in managing real-world data and provides an in-depth tutorial on data cleaning using Python. She uses the FBI's Most Wanted API as an example to explain how APIs and JSON work and how they can be used to extract, manipulate and clean data. Evan covers how to retrieve data via an API, convert JSON data to a Pandas dataframe, and then clean the data. Data cleaning is necessary due to the complexity of the data structure and the presence of missing, nested, or irrelevant data.
(read more)
Additional Projects
data engineering / data science
computer vision and GANs, generating faces from celebrities
computer vision and GANs
the Biwi Kinect Head Pose dataset
Teaching a model to recognize 37 different breeds of dogs and cats
using Fast.ai with tabular data
image classification
image classification
a deep learning app that classifies images based on biased, mainstream beauty standards
a deep learning app that classifies images of three types of bears with 100% accuracy
a deep learning app that classifies images of dogs and cats with 100% accuracy
a deep learning app that classifies images human faces as happy, sad, or angry
article covering the three above projects
Deep learning image classification
image recognition and classification
using neural networks to predict life expectancy
a comprehensive introduction to PyTorch
data analysis and visualization
profit and customer analysis with Tableau
using SQL to manage an employee database
natural language processing with TensorFlow
a personal data investigation into long covid
NYC taxi prediction with XGBRegressor
a look at dynamic programming through image manipulation
Australian rainfall prediction with a random forest model
house price predictions with linear regression
finding patterns in UFO sighting data
a curriculum organization and maintenance webapp
copyright © 2023 IHeartComponents